1 Introduction
training 이후, test를 할 때 대부분의 attention head 를 remove해도 된다.
encoder- decoder layer는 pruning에 민감하게 반응, multi head가 무언가 중요한 역할을 함. training 을 통해서 중요하고, 안중요한 head 들이 생김을 알 수 있음.
2 Background: Attention, Multi-headed Attention, and Masking
2.3 Masking Attention Heads
특정 head의 영향을 배제하기 위해 masking을 진행. 그 경우 식은 아래와 같음.
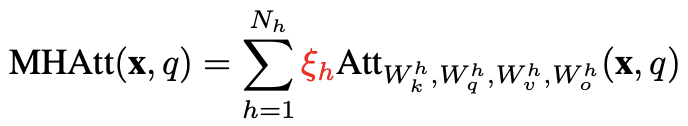
3 Are All Attention Heads Important?
한 개 이상의 head를 remove하면서 변화를 관찰.
3.1 Experimental Setup
WMT와 BERT 두개의 model을 사용.
WMT(6layers and 16 heads per layer)
features 3 distinct attention mechanism (enc-enc / enc-dec / dec-dec)
BERT(12 layers and 12 heads)
fetures one attention mechanism (self attention in each layer)
위의 것 중 WMT의 enc-dec 만 self-attention 아님
3.2 Ablating One Head
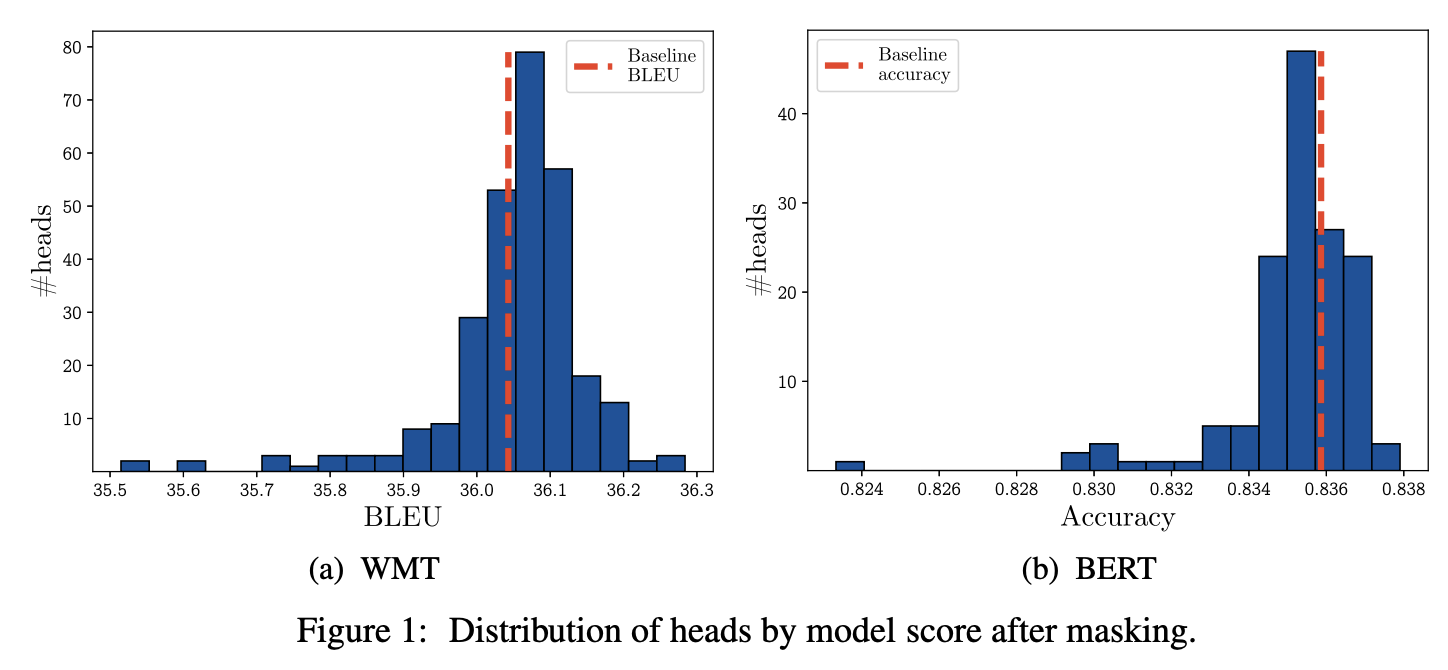
Figure 1a and 1b -> 대부분의 head를 제거해도(하나씩) 성능은 비슷하게 나옴. 더 잘 나오는 경우도 있음
큰영향을 주는 것은 소수다.
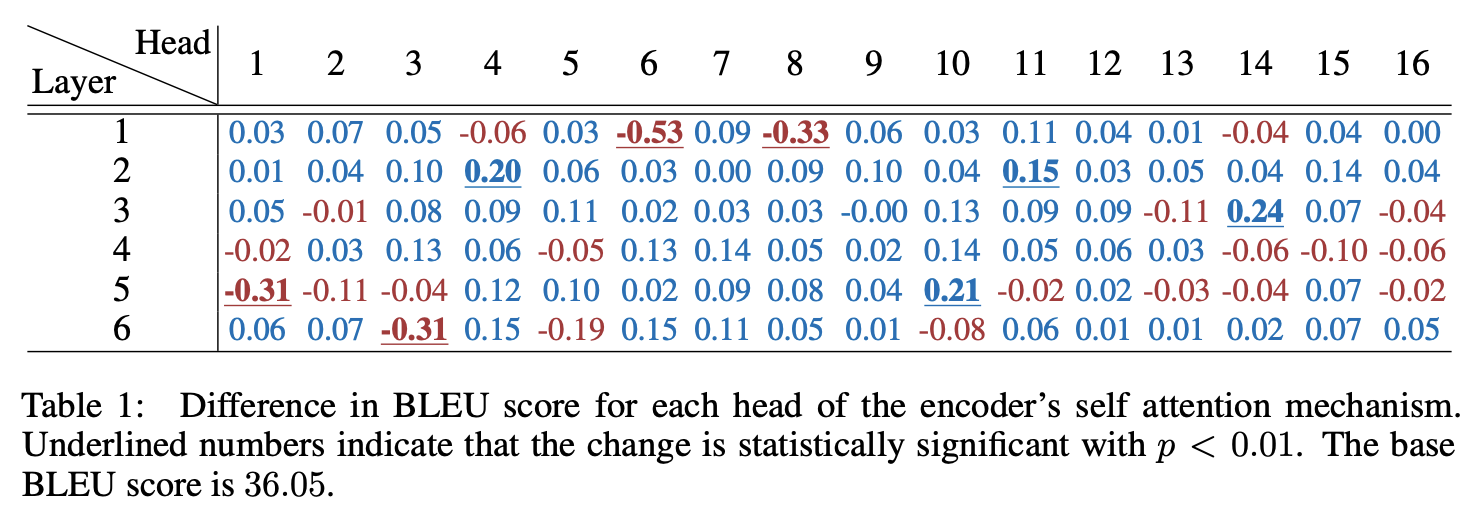
statistically significant : 같은 분포에서 이런 결과가 나올 가능성이 0.01 보다 작다
Table 1 -> 96개중 8개만 의미 있게 큰 값을 가짐(제거됐을 때 큰 영향, 사실 절반은 제거했을 때 더 큰 BLEU값 나옴)
-> test time에서 대부분의 head 는 중복됨.
3.3 Ablating All Heads but One

가장 중요한 head(best head)를 남겨 두었을 때 변화를 측정한 결과, test 단에서는 head를 하나만 남겨도(나머지 layer head 는 그대로 둔채) 큰 변화가 없음을 알 수 있다 . WMT의 경우 가장 마지막, 13.5 BLEU차이가 나는 부분 정도만 차이가 있음을 볼 수 있다.
이는 "best on its own"이 아닌 경우에도 성립한다. 50%정도의 경우 하나의 head 만 남겼을 때 큰 퍼포먼스 차이가 나타나지않는다.
3.4 Are Important Heads the Same Across Datasets?
중요한 head 가 다른 곳에서도 중요한 역할을 하는가?
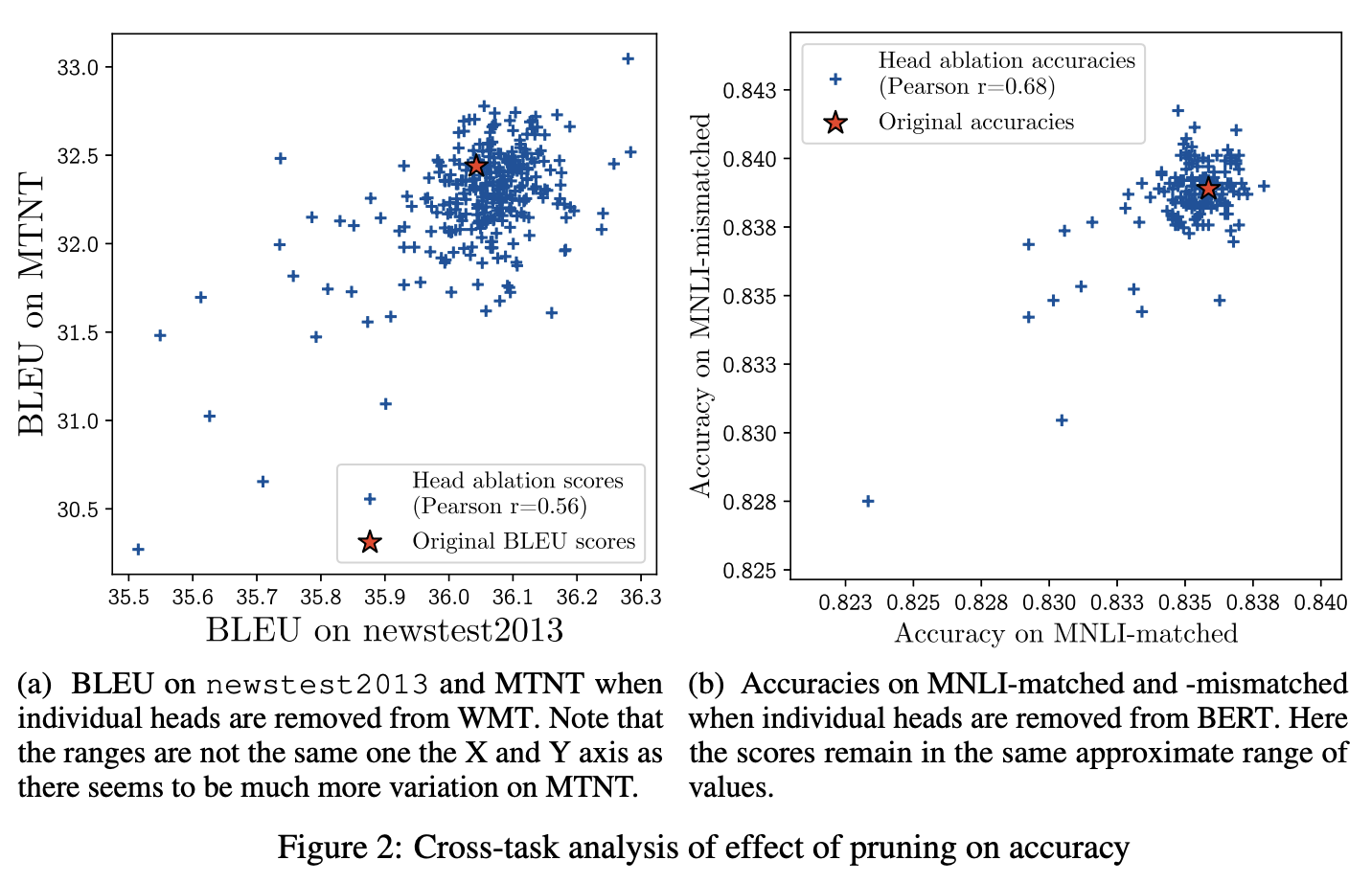
Figure 2a, 2b -> has positive >0.5 correlation between the effect of removing a head on both dataset.
"universally" 중요한 head가 있다.
4 Iterative Pruning of Attention Heads
head를 하나씩 제거해나갈 때의 영향을 확인하기 위해서 중요하지 않은 순서대로 정렬하고, 하나씩 없애 나가봄
4.1 Head Importance Score for Pruning
mask variable ξh 에 따른 expected sensitivity of model 을 나타낼 식을 다음과 같이 선언하고, 여기에서는 Attn(x)를 이용해 아래와 같이 나타내었다.

4.2 Effect of Pruning on BLEU/Accuracy
20~40%까지 I(h)가 낮은 순으로 제거를 진행했을 때에는 별다른 부정적 효과가 나타나지 않았지만 조금 더 경과했을 때에는 추가적인 retraining 없이는 부정적 효과가 나타남을 볼 수 있다.

4.3 Effect of Pruning on Efficiency
memory와 inference speed 관점에서 매우 효과를 보임을 알 수 있다.

Table 4에서 볼 수 있듯이, batch size에 따라 최대 17.5%까지 inference speed 의 향상을 볼 수 있다.
5 When Are More Heads Important? The Case of Machine Translation
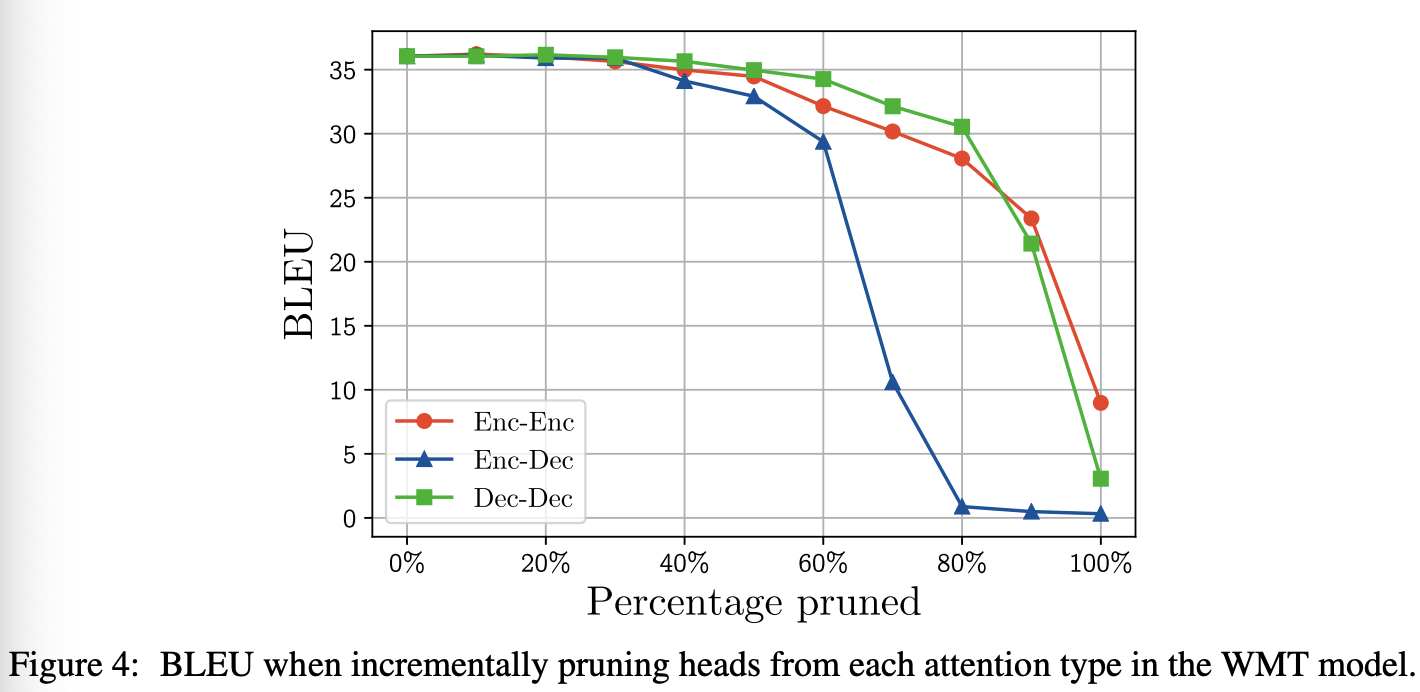
Figure 4를 보면, enc-dec의 경우가 다른 것들에 비해 multi-headness의 영향을 많이 받음을 알 수 있다.
6 Dynamics of Head Importance during Training

Figure 5를 보면, epoch초반에는 prune이 진행된만큼 Linear하게 성능이 떨어지다가, epoch이 10정도를 넘어가면 성능이 유사하게 유지됨을 볼 수 있다. -> important head 가 빠르게 결정된다(즉각적이진 않음)
8 Conclusion
몇개의 head는 test performance에 큰 지장없이 remove 될 수 있다. 그리고 machine translation model에서는 encoder-decoder atttention layer가 multi head 에 가장 많은 영향을 받음을 알 수 있었고 각 head의 relative importance 가 학습 초기에 결정됨을 알 수 있었다.
꽤 많은 head 를 빼도 됨, 단순 greedy 보다 더 효율적으로 head 를 제거하는 방법도 존재.
하지만 왜 그런지에 대한 해답을 제시하지는 않음.


