1 Introduction
NLP 문제를 해결함에 있어서 Transformer 형태를 이용한 방법들이 많은 효과를 보았다. 그러나 self attention과 parallelizable recurrence, 엄청나게 높은 performance의 hardware, pre-training step등에서 상당히 많은 시간이 소모됨을 볼 수 있다.
이 논문에서는 pre-training transformer network의 속도를 향상시키기 위해 training 테크닉과 구조의 변화를 소개한다.
layer수를 줄이거나, stochastic depth를 시도해보는 것이 효과가 없었다고 한다.
(stochastic Depth란?) -> 네트워크의 길이를 효과적으로 줄이기 위해 무작위로 레이어 전체를 뛰어넘도록 하였다.
논문에서는 다음과 같은 과정으로 접근해 나간다.
i) 왜 transformer network에서는 stochastic depth를 이용해 학습하는 게 어려울까?
-> transformer architecture의 선택, training dynamics 모두가 layer dropping 에 큰 영향을 미친다
ii) Switchable-Transformer (ST) 이라는 새로운 block을 제안.
allows switching on/off a Transformer layer for only a set portion of the training schedule, excluding them from both forward and backward pass
(training 에서 transformer layer를 사용하는 부분/ 안 사용하는 부분을 switching 할 수 있게 한다?)
&
Transformer network training를 안정화
iii) progressive schedule
to add extra-stableness for pre-training Transformer networks with layer dropping
-> trian이 진행될 수록 Mini-batch에서 Layer drop의 비율을 늘려나간다. (global layer dropping rate를 이용해 서로 다른 layer에도 같은 값을 제공해준다?)
iv) 결론적으로 BERT에 적용시켜보았을 때 같은 샘플에 대해 24% 빨라졌고, pre-training 은 2.5배 빨라짐을 볼 수 있었다.(비슷한 정확도)
2 Background and Related Work
BERT와 같이 transformer layer가 쌓여진 구조의 성능이 좋아서 많이 쓰였는데, 계산량과 시간이 너무 많이 소요되어서 이를 해결하기 위한 방법을 찾는데, 보통 total number of floating-point operations(FLOPS)가 layer의 수와 비례하므로 이것을 줄여본 결과, 성능이 많이 저하됨을 볼 수 있었다.
딥러닝에서 주로 stocastic depth(임의의 layer drop하는거?)를 시행하는데, 이것이 BERT에서는 stability가 저하됨을 알 수 있다. 왜인가?
3 Preliminary Analysis
BERT에서의 PostLN and PreLN의 비교 / sparial, temporal dimension에서의 dynamic 측정/ layer를 제거했을 때 나타나는 효과를 비교해보았다.
3.1 Training Stability: PostLN or PreLN?
PostLN :

PreLN :

Fig1 ->PostLN에는 unbalanced gradient(e.g. vanishing gradients as the layer ID decreases) 문제 발생, ReLN에서는 이 문제는 없고, gradient norm의 크기가 거의 비슷
PostLN이 hyperparameter를 찾는데 더 민감, and training often diverges with more aggressive learning rates
반면, PreLN은 vanishing gradient 를 피하고, 더 안정화된 optimization 실행.
3.2 Corroboration of Training Dynamics
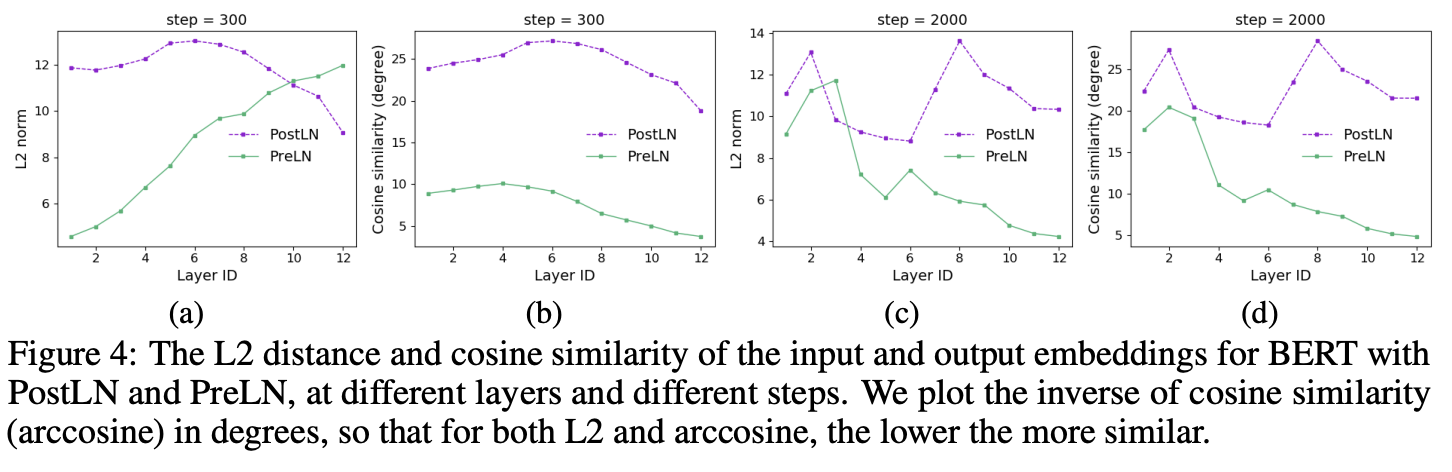
training이 진행된 후에, PostLN에 비해, PreLN의 dissimilarity가 상대적으로 많이 줄어드는 모습을 볼 수 있다.
-> PostLN이 layers 별로 매우 다른, 새로운 representation을 생성하려고 할때, PreLN의 dissimilarity가 줄어드는 모습(upper layer들이 비슷한 estimation을 가지고 있다.) 는 것을 의미.
unrolled iterative refinemen(?) 를 실행할 때, 이미 성공적인 layer는 전체를 다시 계산하기보다는 이전의 것을 가져온다?
3.3 Effect of Lesioning
PreLN이 포함된 layer를 PostLN이 포함된 layer보다 더 많이 drop시키면, 실행 결과에 미치는 영향이 적을 것이라고 생각할 수 있다.
4 Our Approach: Progressive Layer Dropping
4.1 Switchable-Transformer Blocks
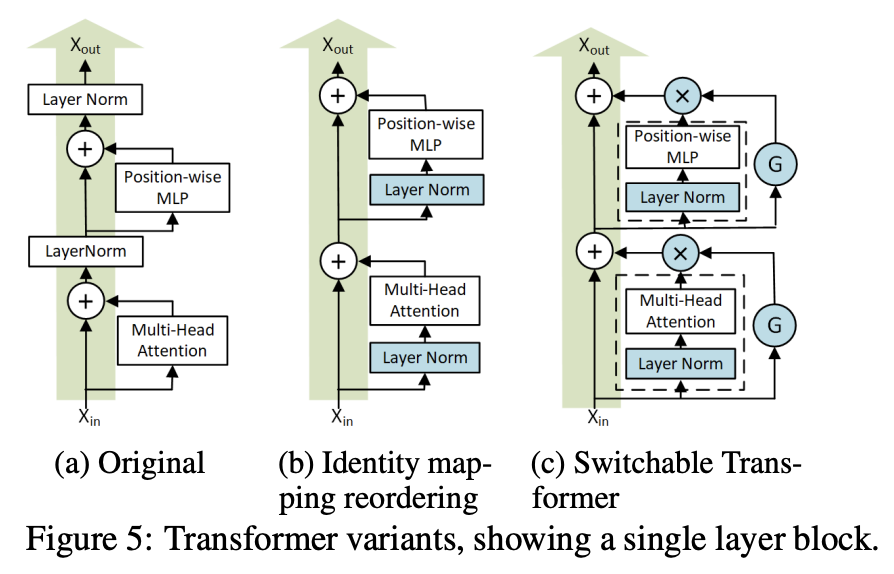
Identity mapping reordering 5-(b)
Layer Norm을 input단에다가만 넣는 식으로 바꿔준다.
Switchable gates 5-(c)
Conditional gate funciont G를 도입하여 해당 sublayer를 사용할지 말지 정한다.
이때 G는 0과 1로 이루어져 있으며, 베르누이 분포를 따른다. , Gi ∼ B(1, pi)

4.2 A Progressive Layer Dropping Schedule
3.2에서 curriculum learning 에 영감을 받음. curriculum learning = 쉬운 데이터를 먼저 학습.
temporal scheduling을 위해 θ(t) 도입 - 보유할 ST block의 갯수를 정하는 함수
Progress along the time dimension.
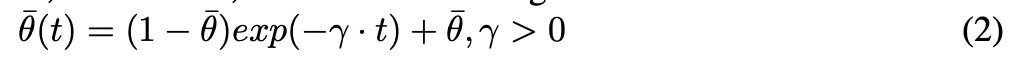
처음에 θ(0) = 1 이고 점점 줄어들게
Distribution along the depth dimension

lowe level에 더 낮은 drop late를 할당하기 위한 식.
두 식을 합쳐서 다음과 같은 progessive scheduling 실행

identity mapping 의 존재로, ST block이 특정 Iteration을 위해 우회해 들어갈때, forward-backward computation이나 gradient update 가 필요하지 않고, 짧아진 network와 각각의 layer의 더욱 직접적인 경로로 update 가능하다.

여태까지의 내용을 모두 합치면 옆과 같은 알고리즘을 제안할 수 있다.
네트워크의 깊이를 L이라고 하면, θ = 0.5일 때 예상하기로 3L/4정도로 dropping이 가능하다. -> 25%정도의 FLOPS save 가능
5 Evaluation



