1. abstract
can we further improve performance of ViTs by making it deeper, just like CNNs?

figure 1. block 개수와의 연관성. block 수가 늘어난다고 무조건 향상하는 것은 아님. 32 layer의 경우 24layer보다도 적은 accuracy를 나타냄.
특정 layer개수를 지나면 값이 수렴하는 모습을 볼 수 있는데, 이를 attention colapse라고 부르기로 함.
: ViT가 깊어지면, rich representation을 보기 위한 diverse attention이 필요하지 않게됨. : self-attention의 효과가 적어짐
이를 방지하기 위해 Re-attention 이라는 새로운 메커니즘 제안 :
multihead, 다른 head의 정보를 가져오는 방식. -> figure 1과 같은 성능 향상
2. Related Work
2.1 Transformers for Vision Tasks
2.2 Depth Scaling of CNNs
3.2 Attention Collapse
Fig 1.을 보면 모델이 깊어질 때, 정확도가 빠르게 수렴하는 모습을 볼 수 있다.
이는 CNN과 다른 양상을 보이며, ViT에서 중요한 역할을 하는 self-attention에 집중하여 살펴보았다.
-> model이 깊어질수록 attention map이 어떻게 분포하는지 측정
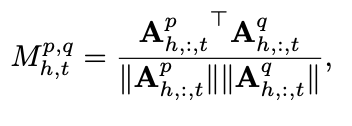
attention map이 어떻게 발달하는지 지켜보기 위해 다음과 같은 수식을 이용하여 cross-layer similarity를 계산하였다.
(layer p,q 사이의 유사도, 특정 h번째 head 에 대한 t차원 벡터)
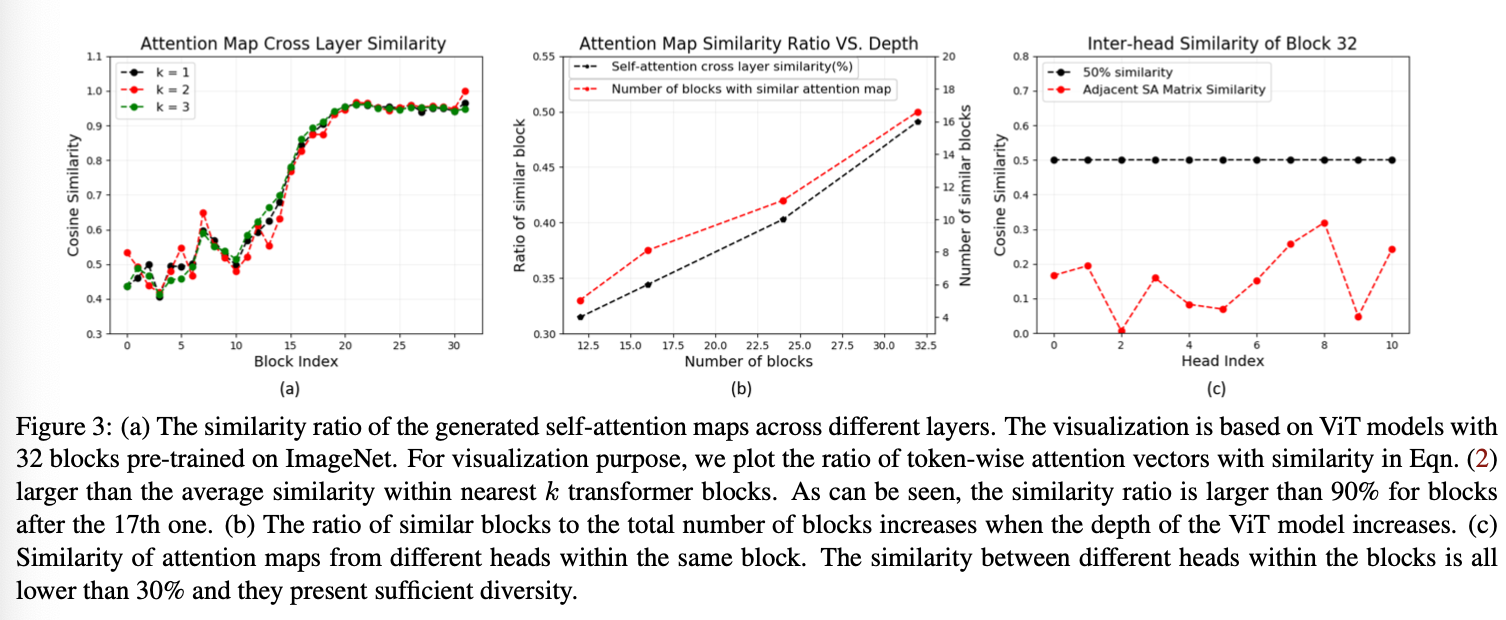
Fig 3-(a) : M이 17보다 커질때, 유사도가 90%를 웃돈다 : transformer blocks degeneragte as MLP
, 그리고 MHSA의 rank도 감소하게 된다.
Fig 3-(b) : 유사도를 transformer의 block 크기를 다르게 하며 측정했을때 : block이 늘어날수록 ratio of similar block이 증가함.
Fig 3-(c) : head 의 개수 변화에 대해서는 모두 30%이하의 유사도를 가졌다는 건가?

20th block 이후 similarity는 높고, learned feature는 더 발전하지 않았다. : attention similarity와 feature similarity의 상관관계가 있을 것이다.
4. Re-attention for Deep ViT
4.1. Self-Attention in Higher Dimension Space

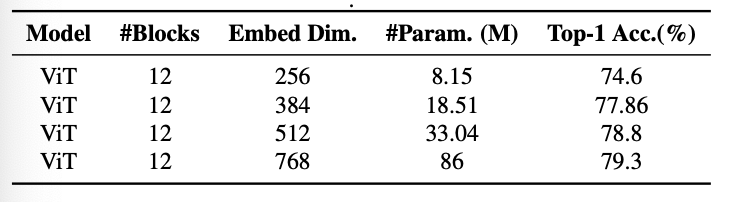
위의 그래프와 표를 보면, embedding demension이 증가하면, accuaracy가 증가하고, similar block의 수가 줄어들지만 parameter의 수는 제곱으로 늘어남을 볼 수 있다. 이 현상을 응욯애서 self-attention의 hidden dimension을 증가시키고, novel re-attention mechanism을 적용시킴으로써 새로운 모델을 제안한다.
4.2. Re-attention
fig3-(c)를 보면 서로 다른 head 들은 다른 영역을 보고 있는 것을 볼 수 있다. attention map을 re-generate 하기 위해 cross-head communication을 제안한다.
transformation matrix를 제안하여, 이를 이용하여 multi-head attention map에서 새로운 것을 뽑아낸다.

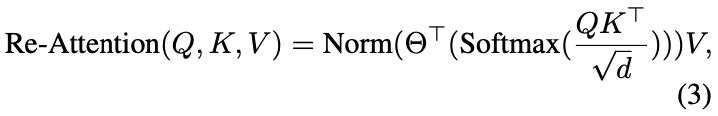
layer-wise variance를 줄이기 위해서 normalization 추가
장점 : attention head 사이의 interaction을 통해 complementary information을 수집, attention map의 다양성을 늘린다.
5.1. Experiment Details
모두 같은 hyper parameter, AdamW optimizer, cosine learning rate dacay policy (initial learning rate : 0.0005) 사용.
8 Telsa-V100 GPU, 300 epochs / batch size : 256
mixup, random augmentation 사용 / ImageNet dataset 사용
embedding demensio : 384에서 시작, 3배씩 늘림. 12개의 Head 사용.
5.2. More Analysis on Attention Collapse
attention reuse : ViT 초기 block에서 계산한 attention map을 다시 사용. share the Q and K values of the las "unique" block to all the blocks afterward. 여기서 unique block이란 주변 Layer과의 유사도가 90%보다 작은 것을 의미.

32개의 블럭의 경우, 15부터 같은 값을 썼을 때, 정확도의 감소량이 매우 미미하다.
Visualization : learned attention map을 visualizaiton

기존의 MHSA의 경우, 앞부분만 주변 조각들과의 Local relationship을 찾았고 이후에는 전반적으로 전체를 보는 모습을 볼 수 있다.
local : 자기자신만 보는 것처럼
(row wise 로 줄이 생긴거 : 모두 똑같은 값으로 weight 주면 attention 의미X)
Re-attention을 적용시킨 경우, deep block에서도 다양성을 보이고 주변 block과 유사성이 적은 모습을 볼 수 있다.
다양성을 잃는 성질을 방지할 수 있음
5.3. Analysis on Re-attention
Re-attention v.s. Self-attention: re-attention을 적용시킨 경우, similar block의 수가 확실히 줄어듦.-> attention collapse 문제를 해결했음을 보임.
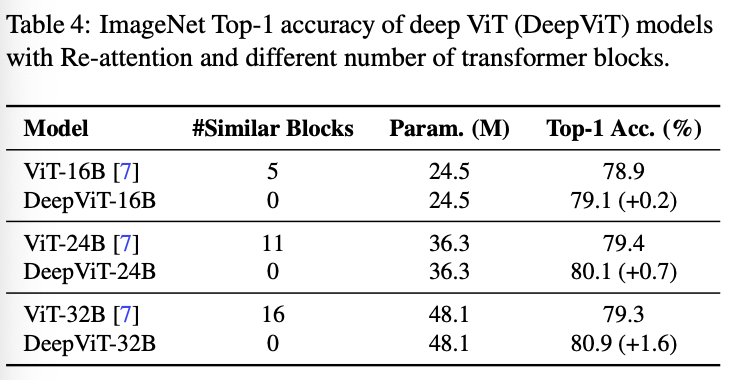
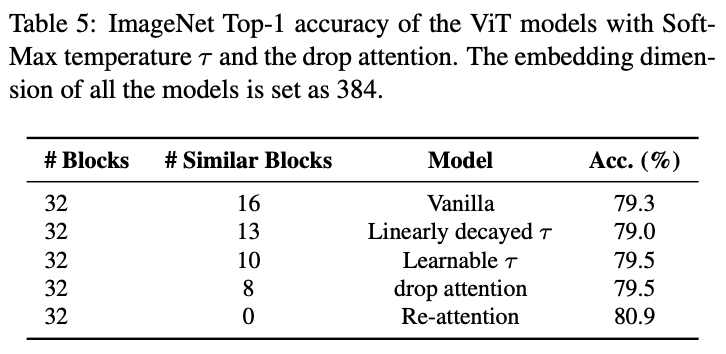
기본적인 ViT외의 다른 Model 과 비교해봤을 때도 similar block의 수가 현저히 적음을 볼 수 있다.
(Linearly decayed r : 루트 d 앞에 곱해져서, over-smoothing 방지)

Advantages of Re-attention : temperature-tuning 을 진행한 model이나 attention-dropping을 진행한 model 보다돈 좋은 성능을 나타낸다. 두 경우는
regular- izing the distribution of the originally over-smoothed self- attention maps, without explicitly encouraging them to be diverse
이지만 re-attention의 경우 서로 다른 head를 basis로 attentionmap을 재생성한다. 8(c)를 보면 learned transformation matrix가 weight를 다양하게 할당함을 볼 수 있다.


