1 Introduction
이전의 모델들은 hidden layer h(t)를 구하기 위해 input과 h(t-1)값을 참고하는데, 메모리 제약 등으로 인해 긴 문장들에게는 critical 하게 됨.
attention mechanism을 이용하면 거리에 상관없이 영향을 구할 수 있음.
이 논문에서는 새로운 모델로 Transformer를 제안하는데, attention mechanism에 의존하여 input과 ouput의 global dependencies를 구해준다.
2. Background
Extended Neural GPU [20], ByteNet [15] and ConvS2S -> 거리가 멀어지면 그 관계성을 찾기 힘들다.
Self-attention : 서로 떨어져 있는 비슷한 문맥의 단어들을 비슷한 문맥으로 파악할 수 있게함.
End-to-end memory networks : seqeunce-aligned recurrance 가 아닌 recurrent attention mechanism을 사용.
Transformer : seqeunce aligned RNN이나 convolution 대신 self-attention 을 이용하는 첫 transduction model
3 Model Architecture
encoder 와 decoder로 이루어져 있음.
encoder : input으로 들어온 symbol representation (x1,...,xn)을 continuous representation z = (z1,...,zn)으로 바꾸어줌
decoder : z를 (y1, ..., ym)로 바꾸어줌.
각각의 step은 auto-regressive(random?) 하고, 이전 step의 symbol 값이 다음 step의 input에 합쳐진다
3.1 Encoder and Decoder Stacks
Encoder : 2개의 sub-layer를 가진 6(N=6)개의 identical layer로 이루어져 있는데 하나는 multi-head self-attention mechanism 이고, 다른 하나는 simple, position-wise fully connected feed-forward network이다.
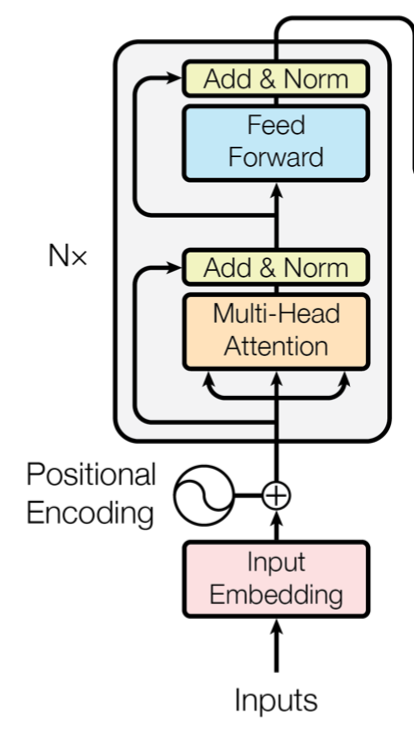
옆에 나와있는 것과 같지 각각은 residual connection되어있고, layer nomalization이 시행된다. 즉, 각 sublayer의 output은
LayerNorm(x + Sublayer(x)) (Sublayer(x) 가 sublayer에서 나온 output값)
과 같이 구성된다.
이런 residual connection을 위해 sub-layer의 output dimension은 모두
dmodel = 512 로 같다.
Decoder :

decoder와 비슷하지만, 3개의 sub-layer를 가진 6(N=6)개의 identical layer로 이루어져 있는데, 이 중 3번째 sub layer는 encoder의 output에 대하여 multi-head attention을 수행한다.
또한 Masked Multi-head attention layer에서는 i번째 이후의 값을 masking 시켜 i번째 값의 prediction에 known outputs i 이전값들만 영향을 미칠 수 있게끔 한다.
3.2 Attention
attention function은 query, key, value를 output 에 매핑하는 것으로 볼 수 있는데, output은 value에 weighted sum을 곱한 값으로 구할 수 있다. (weighted sum은 query와 key를 이용하여 구한다.)
3.2.1 Scaled Dot-Product Attention

dk 차원의 queries와 keys, dv 차원의 values 가 주어질 때 공식은 아래와 같이 수행됩니다.
보통 attention function 에 additive attention과 dot-product attention이 이용되는데, matrix를 이용하여 연산이 빠른 dot-product에 루트 dk로 나누어주어 softmax에서의 단점을 없앤 scaled dot-product attention을 사용하는 방식입니다.

3.2.2 Multi-Head Attention

d-model queries, keys, values를 이용해서 scaled-dot product 를 수행하는 대신에, 각각의 queries, keys, values를 각각의 dimension에 project 하는 것을 h 번 반복하는 multi-head attention을 사용한다.

WiQ ∈ Rdmodel ×dk , WiK ∈ Rdmodel ×dk , WiV ∈ Rdmodel ×dv andWO ∈Rhdv×dmodel
3.2.3 Applications of Attention in our Model
- "encoder-decoder attention" 에서 queries는 이전 decoder layer에서, keys 와 values는 encoder의 output에서 온다. -> decoder의 모든 position이 input sequence의 모든 position에 접근 가능
-> sequence-to-sequence model처럼 동작하게 해줌 - encoder가 self-attention layers를 포함한다. -> previous encoder의 output이 똑같은 key, queries, value를 가지는 것과 attention 을 수행한다.
- decoder 단의 self-attention 도 decoder의 모든 position에 접근가능하게 해준다. auto-regressive property를 막기 위해 decoder 의 leftward information flow를 막아줘야하는데, scaled-dot product 에서 불필요한 connection을 masking 하는 방법으로 이를 해결한다.
3.3 Position-wise Feed-Forward Networks
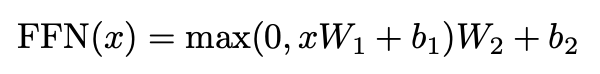
각각의 encoder decoder는 fully connected feed-forward network를 가지고 있는데, 이는 오른쪽 식과 같다.
(max 부분 : ReLU)
linear transform이 모두 같게 동작하기 때문에, parameter를 다르게 해서 적용시켜주어야 한다. 이를 two convolutions with kernel size 1로 표현할 수 있다..?
3.4 Embeddings and Softmax
3.5 Positional Encoding
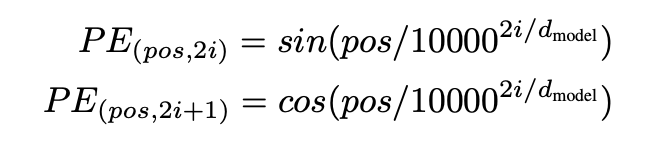
4. Why Self-Attention

세가지 관점에서 비교해볼 수 있다.
그중 마지막은 long-range dependencies를 확인하는 path length를 나타낸다.
또한 추가적인 이점으로, 번역을 하는데에 있어도 좋은 성능을 나타낸다 -> syntactic and semantic structure 를 파악하는데에도 성능이 향상된다.



