가장 간단한 변조를 통해서 image에 attention network를 적용시키기 위한 시도라고 볼 수 있다.
image를 Patch로 나눈뒤에, sequence of linear embedding 을 적용시켜 transformer를 사용하는 방식으로 진행된다.
(교수님께서는 너무 단순한 방법으로 진행됐다고 하셨던.. 논문)
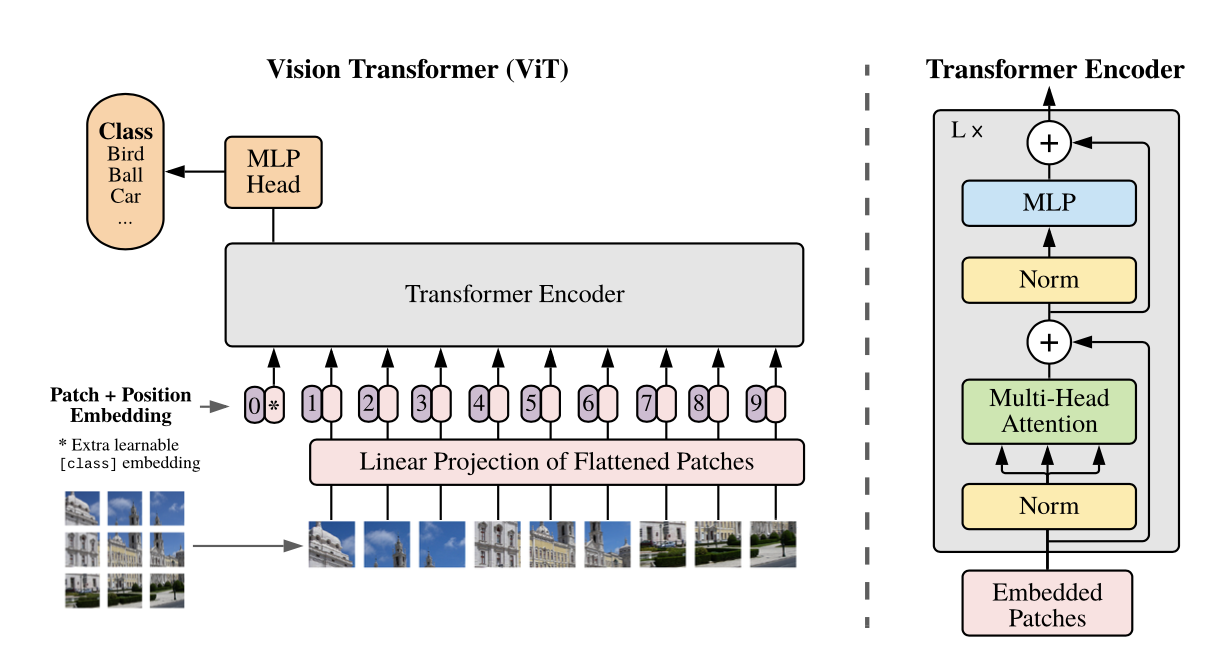
model 구상은 위와 같습니다. Image를 고정된 크기로 분할하고, position embedding을 더해줍니다. 이렇게 구성된 조각을 Transformer Encoder의 입력단으로 넣어줍니다.
3 METHOD
3.1 VISION TRANSFORMER (VIT)

이미지를 (P,P) 로 분할하여 patch를 생성한 후에, constant latent vector size가 D로 고정되어 있기 때문에 이로 flatten하고
trainable linear projection를 수행합니다. projection의 output을 patch embedding 으로 참고합니다.
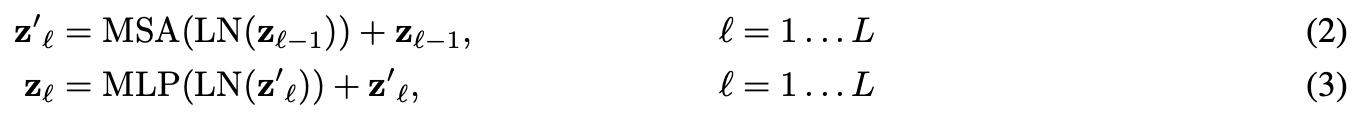
Transformer의 encoder는 (2) (3) 번과 같은 multi-head self- attention block으로 이루어진다.
Inductive bias. : CNN보다 훨씬 적은 수의 inductive bias가 요구된다. CNN은 2차원의 Locality를 가지고 있는 layer들 사이의 정보가 전체 모델에서 이동하지만 Transformer는 MLP단에서만 지역적으로 이용된다.(?) image의 2D position에 대한 정보가 없기 때문에 이웃이나 주변에 대한 정보가 적고, patch 사이의 공간적인 관계는 처음부터(아무것도 모른 상태에서) 학습해야한다.
Hybrid Architecture : 입력단을 raw image patches가 아닌, CNN의 feature map으로 구성할 수 있다. embedding projection (1)식으로 구성되었던 patches를 feature map으로 구성가능.
3.2 FINE-TUNING AND HIGHER RESOLUTION
Typically, we pre-train ViT on large datasets, and fine-tune to (smaller) downstream tasks.
<실험 결론 및 결과는 추후 정리예정>



